


This notes the initial such instance in India, yet the absence of clear plans on AI’s use public information has actually triggered comparable problems internationally. At the core of the problem is AI devices’ ruthless need for top notch information. However, their dependence on conveniently offered on-line info is nearing its restriction. Without broadening their information resources– such as published stories, individual records, video clips, and copyrighted information material– the development of AI chatbots might plateau.
This search of information, nonetheless, is hitting copyright issues and the very carefully created company versions of authors and media electrical outlets.
Read this|Mint Explainer: The OpenAI instance and what goes to risk for AI and copyright in India
The tale thus far
In the United States, authors, artists, and writers have actually taken lawsuit versus AI business for utilizing copyrighted material to educate their versions. Last year, Getty Images filed a claim against Stability AI, charging it of utilizing 12 countless its images to create its system. Similarly, The New York Times submitted a suit versus OpenAI, declaring the abuse of its material and placing the AI business as a straight rival in supplying trusted info. Several authors have actually additionally launched claims with comparable insurance claims.
AI business, nonetheless, mostly say that their language versions are improved openly offered information, which they compete is shielded under reasonable usage plan.
After being educated on substantial datasets, progressed AI versions like OpenAI’s ChatGPT 4.0 and Google’s Gemini 1.0 Ultra have actually accomplished computational performance equivalent to, otherwise exceeding, the human mind. Some of these versions have actually also surpassed people in jobs such as analysis, creating, anticipating thinking, and picture acknowledgment.
Read this| OpenAI vs ANI: Why ‘hallucinations’ are not likely to disappear quickly
To provide specific, error-free, and human-like results, AI systems call for large quantities of human-generated information. The most sophisticated versions, such as these 2, are educated on trillions of words of message sourced from the web. However, this swimming pool of information is limited, questioning concerning just how these versions will certainly maintain their development as conveniently offered info goes out.
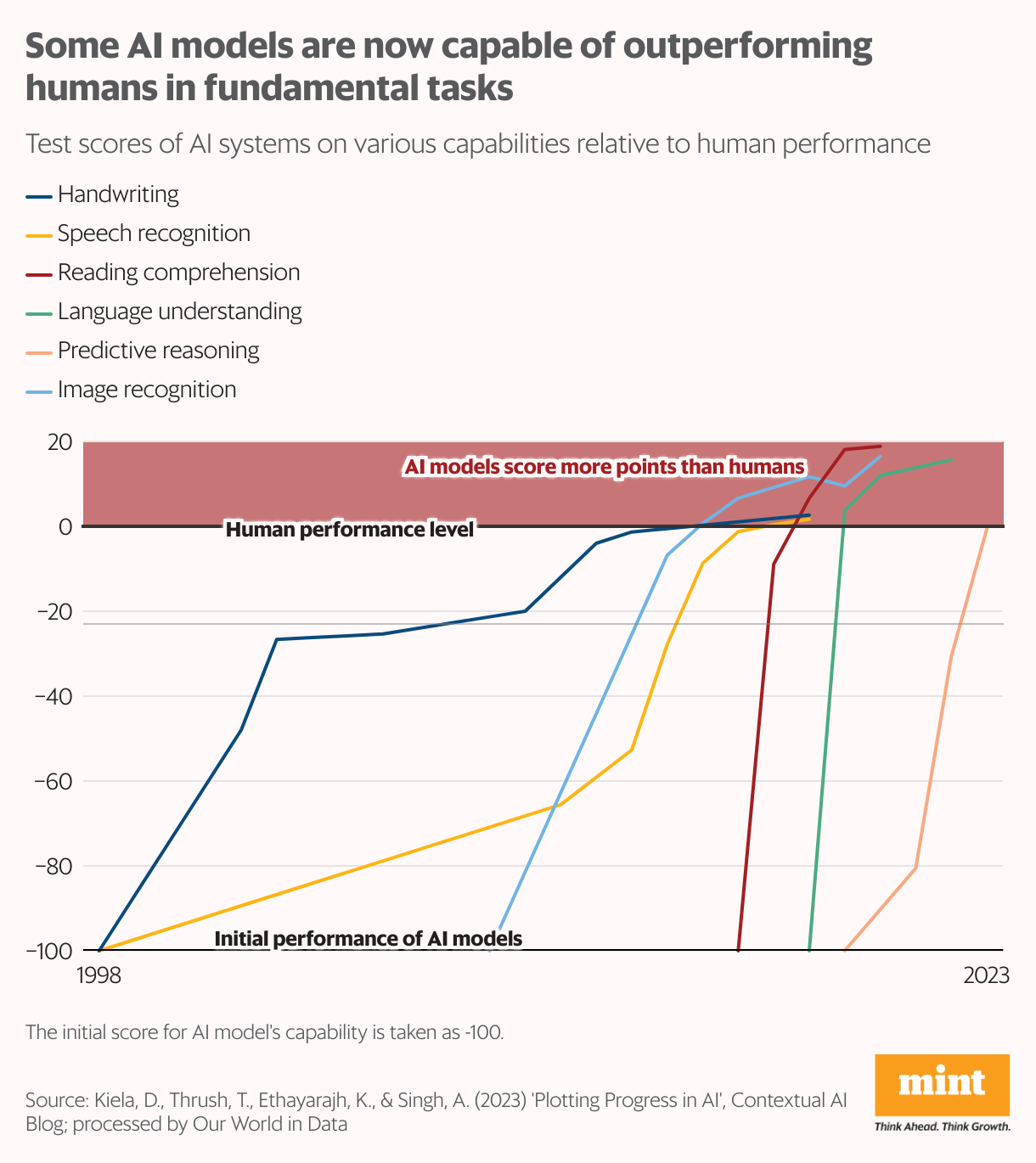
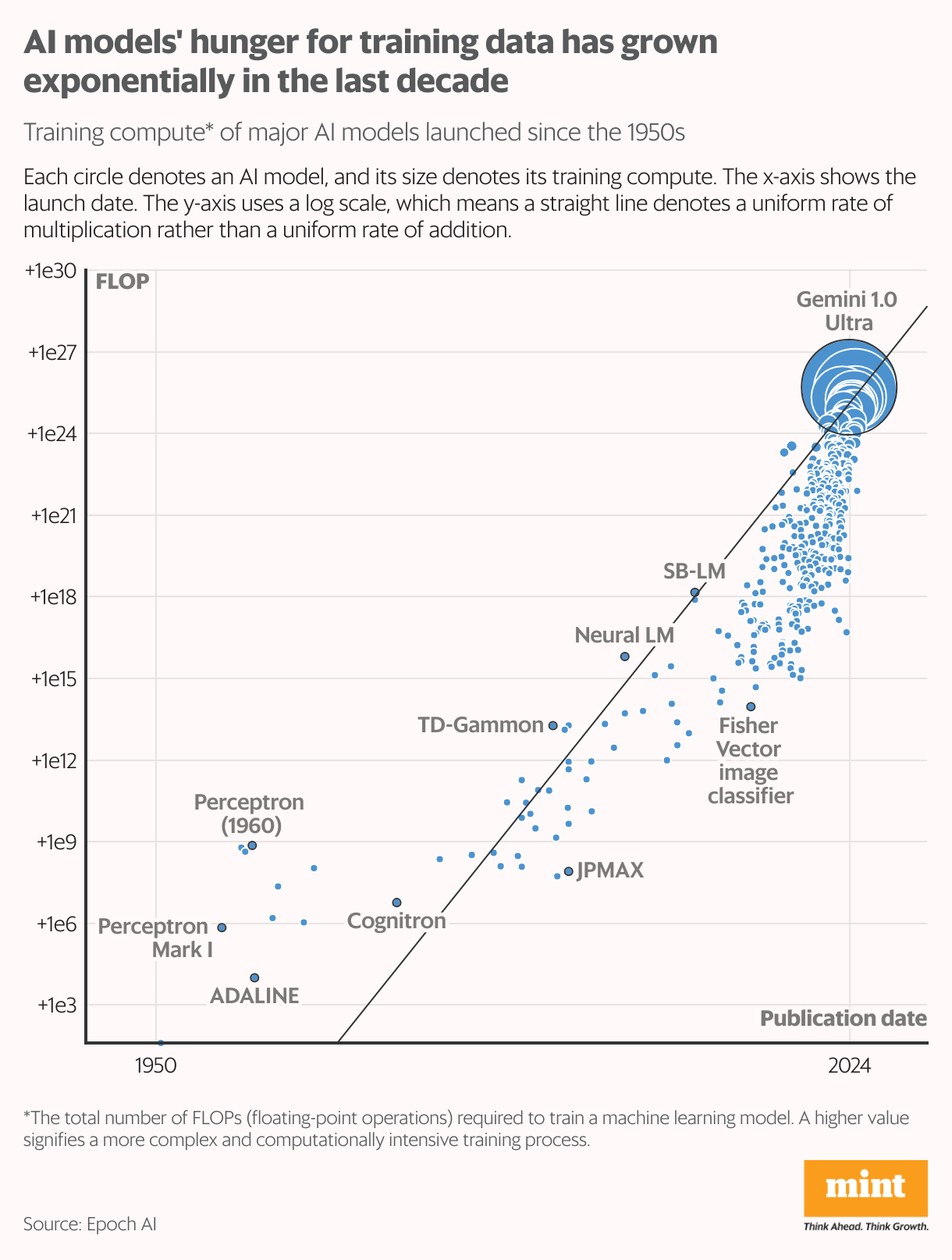
Researchers at Epoch AI quote the web holds around 3,100 trillion “symbols” of human-generated data—though only about 10% is of sufficient quality to train AI models. (A token, in this context, is a fundamental text unit, such as a word, used by AI models for learning.) This stockpile is growing at a sluggish pace, and as large-language models continue to scale, they are projected to exhaust this data supply between 2026 and 2030, according to an Epoch AI study published earlier this year.
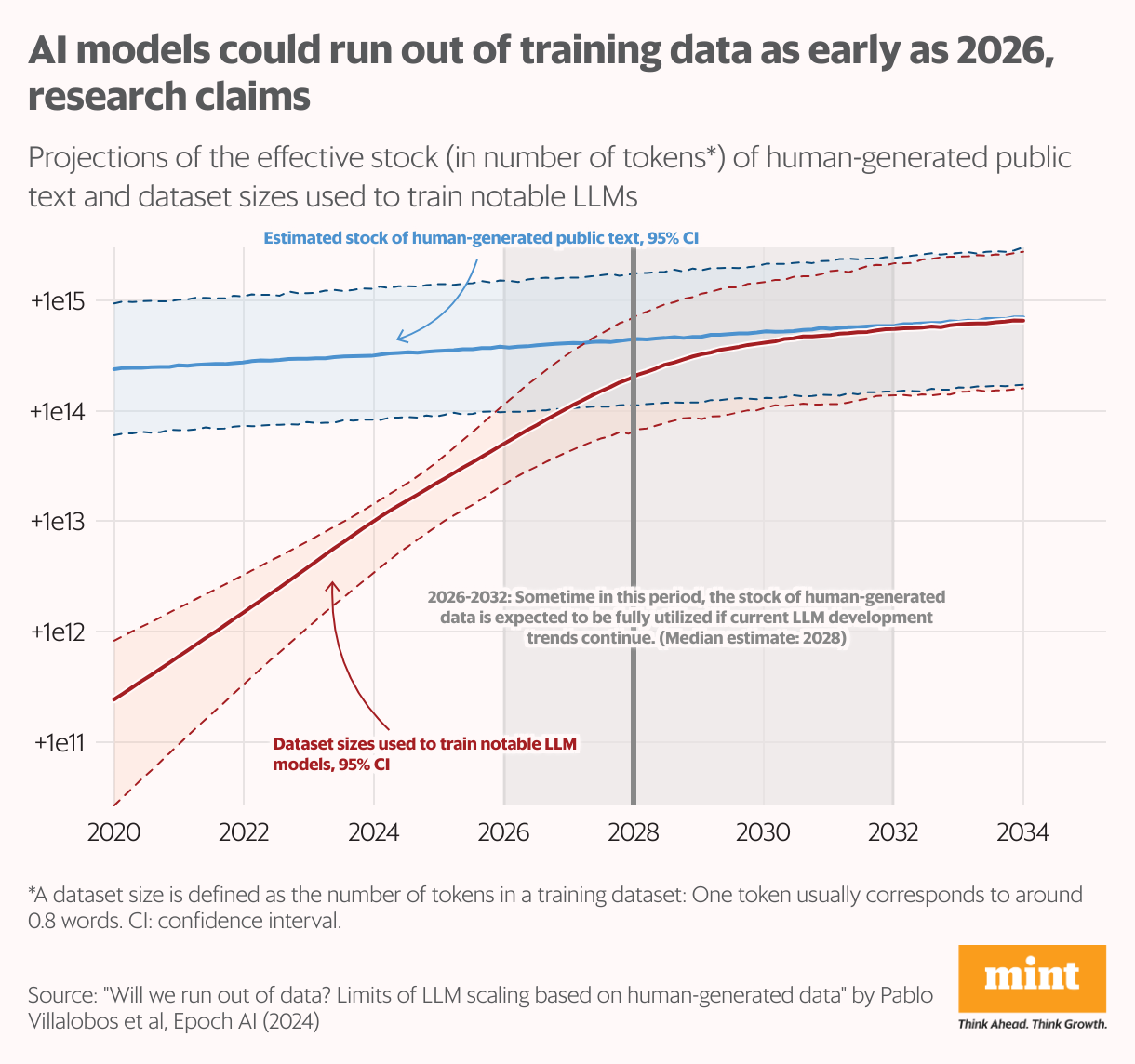
OpenAI, dealing with an information scarcity prior to ChatGPT’s 2022 launch, transformed to unusual techniques. According to a New York Times record in April this year, it produced Whisper, a speech acknowledgment device that recorded countless hours of YouTube video clips right into message, possibly breaching Google’s terms and the legal rights of material makers. Google itself apparently did the very same, and increased its personal privacy plan to permit itself to take advantage of documents in Google Docs and Sheets to educate its robots.
The search
With information in restricted supply, AI business are combing every feasible resource to feed their versions. Students’ jobs, YouTube video clips, podcasts, on-line records and spread sheets, social networks messages– absolutely nothing leaves the ferocious look for information by technology titans.
This ruthless search has actually sustained strong competitors amongst AI business to safeguard financially rewarding information manage authors, usually worth countless bucks. For circumstances, Reddit struck a $60 million yearly manage Google, providing the technology large real-time accessibility to its information for version training. Legacy authors like Wiley, Oxford University Press, and Taylor & & Francis, in addition to information firms such as Associated Press and Reuters, have actually additionally tattooed contracts with AI companies, with some bargains apparently getting to multi-million-dollar appraisals.
Also review|Mint Explainer: What OpenAI o1 ‘reasoning’ version suggests for the future of generative AI
As human-generated information comes to be progressively limited and tough to resource, AI business are transforming to artificial information– info produced by AI versions themselves, which can after that be recycled to produce much more AI information. According to study company Gartner, artificial information is predicted to go beyond human-generated information in AI versions by 2030.
While artificial information provides enormous capacity for AI business, it is not without threats. A research study released in Nature in July 2024 by Ilia Shumailov and associates highlights the threat of “model collapse.” The study discovered that when AI versions indiscriminately pick up from information created by various other versions, the result comes to be susceptible to mistakes. With each succeeding version, these versions start to “mis-perceive” truth, installing refined distortions that duplicate and enhance in time. This comments loophole can create results to wander even more from the fact, endangering the dependability of the versions.
There have actually additionally been efforts to boost the mathematical performance of AI versions, which will certainly permit them to be educated on a minimal quantity of information for the very same result.
Small language versions (SLMs), which are utilized for executing particular jobs utilizing much less sources, have actually additionally ended up being preferred as they assist AI business by not relying upon substantial chests of information to educate their versions. An instance in factor, AI business Mistral’s big language version 7B is developed utilizing 7 billion criteria and the business asserts it surpassed the LLM version Meta’s Llama 2 improved 13 billion criteria on all standards.
Also review|India’s generative AI start-ups look past structure ChatGPT-like versions
The daily grind of chatbots to outmaneuver each various other– and the human mind– is forming the future of innovation. As AI business come to grips with information shortage and copyright fights with authors, the honest effects of their data-hungry quests are impending big.



&w=100&resize=100,70&ssl=1 "India to fill in UNSC board of LeT front TRF’s participation in Pahalgam horror strike–")
